Conformal Prediction
28 September 2025
I originally planned to write about some of the topics I had learned in OxML and include all of them in my OxML blog. Conformal Prediction was the first and so far, the only one I have completed. After some time, I realized that finishing it entirely would take far too long, especially with how busy life has been. So, I decided to let go of this idea for now. Still, I didn't want this write up to go to waste. So, here it is.


Conformal prediction is a tool for quantifying uncertainty in model's prediction. Quantifying uncertainty is especially important in fields such as weather, medical, markets and, LLMs where a faulty model's prediction can have serious impacts to the consumers.
To understand what uncertainty is, imagine training a linear regression model on three different datasets, each having greater variance than the one before.
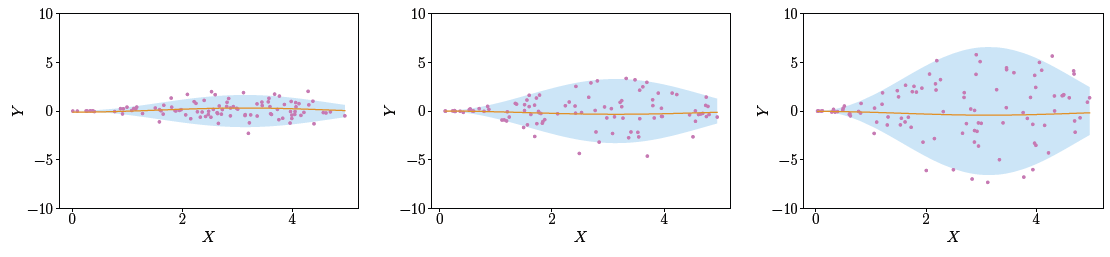
Notice all three datasets look very different from one another. However, the linear regression model seems to have fitted in the exact same way! Clearly, the quality of the model's fit varies across datasets but how do we express them? This is where quantifying uncertainty comes into play.
To put simply, the goal of conformal prediction is to construct a prediction set given such that the probability of falling within is while remaining agnostic to both the model and the data distribution. Formally, it is defined as follows:
PS: One can think of as the confidence interval we learned about in basic statistics!
In this talk, we were introduced to the simplest form of conformal prediction, Split Conformal Prediction. Let's jump right in!
For simplicity, we focus only on the regression case. The idea of classification case is almost the same, you can look it up if you're interested. The procedure is as follows:
- We split the training data, into a training set and a calibration set.
- We train a mean predictor, on the training set.
- We obtain the set of conformity scores using the mean predictor and the calibration set, defined as follows:
- Compute the quantile score of the conformity scores at , denoted by .
- To quantify the uncertainty for , compute as follows:
The prediction set for all possible points can be visualized as follows:
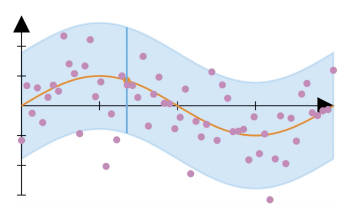
And that's it! The idea is quite intuitive. Essentially, we find the quantile from the set of errors, denoted and (under certain conditions) it can be guaranteed that, on average, the probability of an error exceeding is !
The guarantee requires some assumptions about the dataset. In particular, the dataset needs to be exchangeable, meaning that the joint distribution is the same as the joint distribution of any permutation of the original random variables. Exchangeability is ensured when the samples are i.i.d (independent and identically distributed). Under these assumptions, the theoretical guarantee holds, which can be proven using the quantile lemma. Again, you can look it up if you're interested! (Forgive my laziness!)
However, this method has some flaws. If you look at the previous diagram, you will notice that the size of the prediction set is constant regardless of the properties of the data at a point. This is because when we use a mean predictor , we have no adaptability, since the mean for the dataset is fixed. To incorporate more adaptability, we can use a quantile regressor, instead. The procedure is very similar, with a few differences:
- Definition for computing :
- Definition for computing :
As a result, we achieve greater adaptability, and the size of the prediction set is no longer constant.
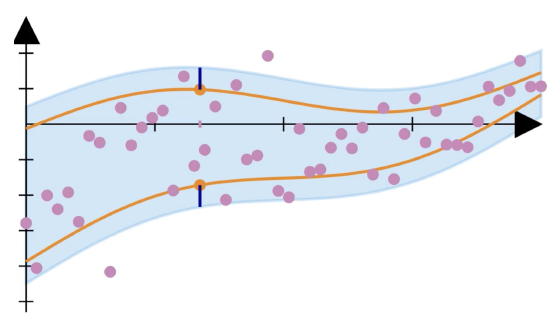
To summarize, Split Conformal Prediction (SCP) is a simple, model-agnostic method for quantifying uncertainty that comes with theoretical guarantees, as long as the assumptions (exchangeable data) are met. However, it is not perfect. First, there is a data splitting issue: when we split our data, we trade off between the model quality and the calibration quality, which is not ideal. Methods such as full conformal prediction does not require data splitting, but they come at a cost to computational efficiency. Second, the thereotical guarantees are only marginal, not conditional: they ensure that prediction intervals contain the true value on average, not for each individual . Third, exchangeability does not hold in many practical applications because data shifts in the real world (e.g., covariate shift and label shift).